
How to make a good impression when saying hello
Digital
You can hear the perfect hello. And now you can see it too. Researchers from the CNRS, the ENS, and Aix-Marseille University1 have established an experimental method that unveils the filter—that is, mental representation—we use to judge people when hearing them say a word as simple as “hello”. What is the ideal intonation for coming across as determined or trustworthy? This method is already used by these researchers for clinical purposes, with stroke survivors, and it opens many new doors for the study of language perception. The team's findings are published in PNAS (March 26, 2018).
- 1The scientists hail from the Science and technology of music and sound research lab (CNRS / IRCAM / French Ministry of Culture / Sorbonne University), the Laboratoire des systèmes perceptifs (CNRS / ENS Paris), and the Institut de neurosciences de la Timone (CNRS / Aix-Marseille University).
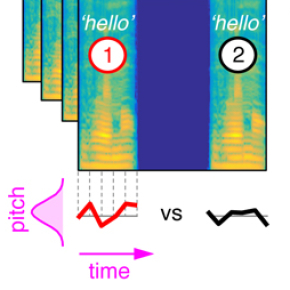
When people you meet for the first time say hello, do they strike you as friendly or hostile? The linguistic and social judgments we make when hearing speech are based on intonation. Just as we have a mental image of what an apple looks like—round, green or red, with a stem, etc.—we form mental representations of others' personalities according to the acoustic qualities of their voices. For the first time ever, researchers have managed to visually model these mental representations and compare those of different individuals.
To do this, they developed a computer program for voice manipulation called CLEESE. This software can take the recording of a single word and randomly generate thousands of other variant pronunciations that are all realistic but each unique in their melody—sort of like putting makeup on the original recording. Then, by analyzing participants' responses when hearing these different pronunciations, the researchers were able to experimentally determine what intonation makes a hello seem sincere. To sound determined, a French speaker must pronounce bonjour (French for “hello") with a descending pitch, putting emphasis on the second syllable (listen / listen) . On the other hand, to inspire trust, the pitch must rise quickly at the end of the word (listen / listen). Using this software, the team is thus able to visualize the “code” people use to judge others by their voices, and has shown that the same code applies no matter the sex of the listener or the speaker.
This method of investigation could be used to answer many other questions in the field of language perception. For example, how do these findings play out at sentence level? And do mental representations vary with the language being spoken? It may also serve to understand how emotions are represented by autistic individuals. To help others answer these questions, the research team has made CLEESE freely available here. The team members themselves have already found a clinical application for the program: to study how words are interpreted by survivors of a stroke, an event which can alter how they perceive vocal intonation. Whether for the purposes of medical monitoring or diagnosis, the researchers would like to use their method to detect anomalies in language perception and possibly make it a tool for patient rehabilitation.
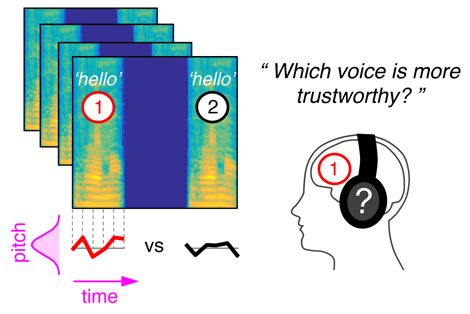
Method used to model mental representations of vocal intonation. Participants consider the intonation of many computer-generated recordings of “bonjour” (“hello”) and decide which, for example, inspire trust. Analysis of thousands of responses makes it possible to visually model a person's auditory mental representations.
Bibliography
Cracking the social code of speech prosody using reverse correlation. Emmanuel Ponsot, Juan José Burred, Pascal Belin & Jean-Julien Aucouturier, PNAS, 26 March 2018. DOI: 10.1073/pnas.1716090115
Contact
Pascal Belin
Aix-Marseille Université researcher
Anaïs Culot
CNRS press office

